Three Popular Leadership Constructs Through the Lens of Their Actual Scales

Three Harvard Business Review pieces from the first quarter of 2026 sit on adjacent territory. Hobson and Depow ask leaders to practice “wise empathy” and present a framework for choosing between sharing and caring. Seth and Edmondson explain how to foster psychological safety on teams that include AI, with Edmondson’s name lending the piece the canonical authority she has earned in the field. Purushothaman and Ammerman describe what authentic leadership looks like under pressure, drawing on a survey of mission-driven leaders and a classroom session at HBS.
Each article invokes a named construct and prescribes action. What none of the three articles does, and what is missing from most leadership writing of this kind, is engage with the measurement instrument that the construct refers to. The instruments exist. They have validation histories. They differ enormously in how well they support the claims the articles want to make on top of them. Reading the articles next to the instruments is a good way to develop the habit of asking what claim is downstream of what data, and that habit is the difference between leadership writing that holds up and leadership writing that does not.
What follows is a walk through the three constructs in the order the articles invoke them, with each construct paired against the dominant scale used to measure it and a short account of where the scale is strong, where it is contested, and what the article’s prescription assumes about it.
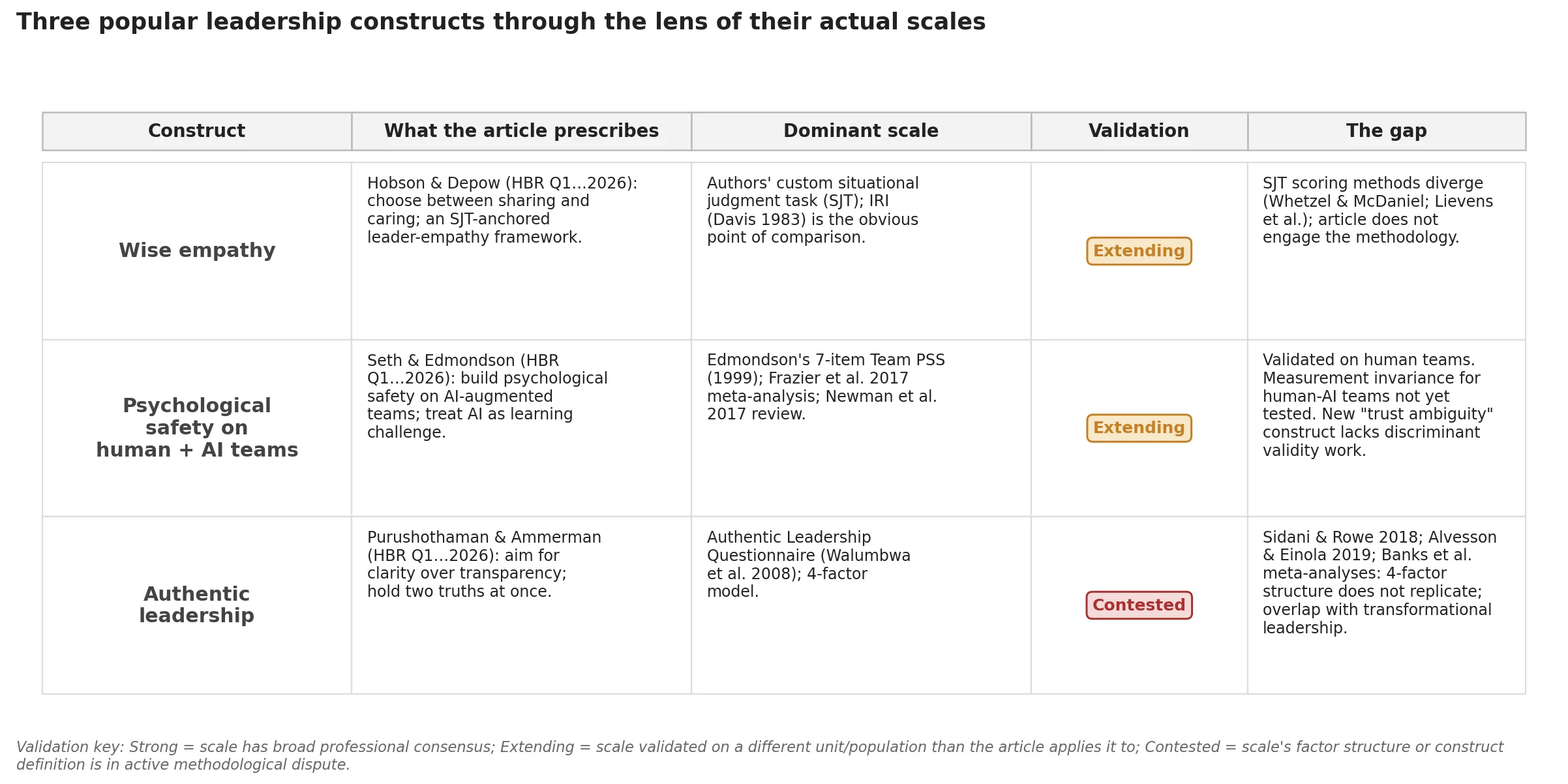
Table of Contents
- The wise empathy framework and the situational judgment task
- Psychological safety, Edmondson’s seven items, and the human-AI team extension
- Authentic leadership and the contested questionnaire it stands on
- The pattern under all three constructs
- What to ask the next time a leadership article names a construct
The wise empathy framework and the situational judgment task
Hobson and Depow build their framework around a measurement instrument they describe in passing. They tell readers they built and validated a situational judgment task to assess leader empathy choices, and the framework that distinguishes care from share emerges from data the SJT generated. That detail is the most informative part of the article for anyone who works in assessment design, because situational judgment tasks are a methodological battleground that the article does not mention.
A situational judgment task presents a respondent with a scenario, usually one or two paragraphs of text describing a workplace situation, and asks them to choose among several response options. The options are designed to vary on the dimension the test is trying to measure, in this case the leader’s empathy mode. The respondent’s selections are scored against a key, and the resulting score is supposed to predict criterion validity outcomes such as job performance or, in this case, leader efficacy and follower engagement.
The methodological battleground starts with how to construct the scoring key. There are roughly three approaches, each with a different validity profile. Theory-based scoring locks in correct answers from a model of the construct, and works only when the theory is precise enough to specify which response is best in each scenario. Consensus-based scoring uses the most common response among a normative sample, and risks measuring what is socially desirable rather than what is effective. Expert-based scoring uses a panel of subject matter experts to define the key, and inherits whatever biases the panel brings. The Whetzel and McDaniel meta-analyses across the 2000s, and the more recent Lievens et al. work, document that SJT validity coefficients vary widely across these scoring methods and that the choice of method is rarely transparent in the publications that use SJTs.
The second issue, well-documented across the SJT literature, is that SJTs are coachable. Respondents who have seen one or two SJTs perform measurably better on subsequent ones, even on different content domains. That bites for any high-stakes use, including leadership assessment in selection contexts. It bites less for descriptive research, but it shapes what a “validated” SJT score actually represents.
The third issue is the gap between cognitive empathy and affective empathy as constructs. Hobson and Depow’s share-versus-care distinction is structurally close to the one that Davis built into the Interpersonal Reactivity Index in 1983, where perspective-taking and empathic concern (the cognitive and affective components) load on different factors and predict different outcomes. The IRI has forty years of validation history across clinical, organizational, and developmental contexts. It is the obvious point of comparison for the SJT. The article does not draw it, and the reader is left to assume that share and care map onto something the IRI literature would recognize. Maybe they do, and maybe they do not. Without the validation evidence, the framework is asking to be taken on faith.
The article also reports a correlation that is less interesting than it looks. Hobson and Depow report that 43 percent of employees gave their leaders lower compassion-focus ratings than the leaders gave themselves. That is a leader-versus-follower scoring discrepancy, and it has its own measurement literature. Atwater and Yammarino’s work on self-other rating agreement, going back to 1992, and the 360-feedback meta-analyses by Fleenor and others, document the pattern as a stable feature of multi-rater assessment, not as a discovery about empathy specifically. The 43 percent figure is consistent with what the broader self-other literature predicts for any positively-valued trait. It tells you the SJT is operating in the same psychometric environment as every other 360 instrument. It does not tell you the empathy SJT discovered something the existing self-other literature did not already know.
The framework Hobson and Depow build is reasonable, the SJT exists, and the recommendations are practical. The thing the article is missing is the methodological humility about what the SJT can and cannot deliver. Treating an SJT as a validated instrument is a strong claim. The cost of paying for the strength of the claim is doing the construct-validity work the article skips.
Psychological safety, Edmondson’s seven items, and the human-AI team extension
Edmondson’s name on the second article matters because the construct of team psychological safety, as it is currently understood in the academic literature, is hers. Her 1999 Administrative Science Quarterly paper introduced a seven-item team-level scale that has since accumulated more validation evidence than almost any other organizational-behavior instrument. Frazier and colleagues’ 2017 meta-analysis pooled hundreds of studies and reported strong relationships between the scale’s scores and team learning, performance, and innovation outcomes. Newman and colleagues’ 2017 review covered the same ground from a different angle and reached compatible conclusions. The construct is real, the scale measures it, and the prescription to “build psychological safety” is downstream of an instrument that has earned the prescription.
The Seth and Edmondson article does something more interesting than restate that history. It introduces a new construct, “trust ambiguity,” and applies the psychological safety apparatus to teams that include AI as a teammate. Both moves are worth examining as measurement claims.
Trust ambiguity, as the article defines it, is a state in which team members believe trust is supposed to be warranted but lack actual trust, and in which the lack of trust feels undiscussable. That definition is structurally close to the existing psychological safety construct, which centers on the discussability of risk-taking and error. Whether trust ambiguity is empirically distinguishable from low psychological safety is a discriminant-validity question, and the article does not answer it. A discriminant-validity test for a new construct typically requires showing that scores on the new construct correlate with scores on existing measures of related constructs, but not so highly that the new construct is just a relabeling of the old one. The article asserts trust ambiguity as a new entity. It does not show that the entity is empirically distinct. Until that work is done, the prescription to address trust ambiguity is hard to separate from the prescription to address psychological safety, which already exists and which the same authors are equipped to prescribe.
The bigger measurement question is what the existing psychological safety scale measures when one of the team members is an AI. The seven items Edmondson built in 1999 were written with a human team in mind. They reference things like “members of this team are able to bring up problems and tough issues” and “no one on this team would deliberately act in a way that undermines my efforts,” with implicit subjects that are people. When you administer the same items in a context where one of the teammates is a generative AI tool, you are asking the respondents to interpret items whose subject reference is ambiguous. Some respondents will read the AI as a teammate. Others will exclude it from the team. The same numerical score across two organizations might mean very different things, depending on how respondents resolved the ambiguity.
This is a measurement-equivalence question. The literature calls it measurement invariance, and the standard statistical test, multi-group confirmatory factor analysis, asks whether the scale’s items load on the latent factor in the same way across groups. For psychological safety in human-AI teams, the test would compare respondents in AI-included teams against respondents in all-human teams and ask whether the factor structure is invariant. To my knowledge, this work has not been done. Without it, applying the existing psychological safety scale to AI-augmented teams is a methodological extension that the validation evidence does not yet support.
None of this is an argument against the article’s prescription. The prescription is to treat AI integration as a learning challenge and apply the principles that work for human collaboration. That is sensible. The argument is that the part of the article that gestures at psychological safety as a measured construct is leaning on a validation history that was built for a different unit of analysis. The construct still works at the prescription level. The measurement work for the new context still has to be done.
I made an adjacent argument about local-versus-population validity in my earlier post on measuring employee engagement when Gallup’s numbers don’t fit your org. The Q12 was validated on a particular population for particular outcomes, and applying it unchanged to a new organization is a methodological extension that vendors typically do not flag. The same logic applies here. Edmondson’s psychological safety scale is one of the strongest instruments in organizational behavior. Strength is local. The validation evidence is for human teams and human team learning. Extending it requires doing the extension work.
Authentic leadership and the contested questionnaire it stands on
The third article, on authentic leadership under pressure, presents a different problem. Where the empathy SJT is methodologically lightly examined and the psychological safety scale is well-validated but contextually extended, the authentic leadership questionnaire occupies a position the article does not engage with at all. The validation history is contested.
The dominant scale is the Authentic Leadership Questionnaire developed by Walumbwa and colleagues in 2008. The ALQ measures a four-factor model of authentic leadership: self-awareness, balanced processing, internalized moral perspective, and relational transparency. The scale was published in Journal of Management, has been used in hundreds of studies, and is the instrument behind almost every empirical claim about authentic leadership in the management literature.
It is also the subject of a sustained methodological critique. Sidani and Rowe’s 2018 review in The Leadership Quarterly is the most comprehensive case for treating the construct as theoretically and empirically problematic. They argue that the four factors do not consistently emerge from the data, that the scale shows substantial overlap with transformational leadership, and that the construct as currently operationalized is doing less independent work than its proponents claim. Alvesson and Einola’s 2019 piece in The Leadership Quarterly is harder still, arguing on theoretical grounds that authentic leadership conflates a normative ideal with a descriptive measurement and that the resulting construct is structurally incoherent. Banks and colleagues’ meta-analyses have reported that the ALQ’s four factors collapse onto a single general factor in many samples, which means the scale may be measuring something useful but is not measuring the four-factor structure it claims to measure. The discriminant evidence (showing the four factors are distinct from each other and from transformational leadership) and the convergent validity evidence (showing each factor correlates with same-construct measures) both point in the same direction, which is that the scale’s internal structure does not hold up under serious examination.
This is not a fringe critique. It is the consensus methodological position among scholars who have looked closely at the scale, and it is sufficiently well-established that any current empirical work on authentic leadership has to engage with it.
The Purushothaman and Ammerman article does not. The article uses the term authentic leadership throughout, presents a survey of 300 leaders and a classroom discussion of 100 more, and reports four patterns and three lessons. The methodological details of the survey are not shared, the instrument used to measure authenticity is not named, and the construct’s contested status in the literature is not mentioned. The article is fine as practitioner reflection. As a contribution to what authentic leadership looks like, it is making claims downstream of an instrument that the field is currently fighting about.
Two things follow. The first is that any reader making decisions on the basis of the article should know they are working with a construct whose measurement is contested. The prescription to lead with clarity and hold two truths at once is not contingent on the ALQ being valid; the prescription survives any of the methodological positions in the literature. But the framing of the article, which treats authentic leadership as a known thing, leaves a reader without the information needed to calibrate how much weight to put on the substantive claims.
The second is more constructive. There is a defensible alternative to the authentic leadership construct that the article could have used. Goldman and Kernis’s work on authenticity, going back to the early 2000s, treats authenticity as a four-component personality construct distinct from leadership, with its own measurement scale (the Authenticity Inventory). That scale has its own validation history, considerably less contested. A piece on what authenticity-the-personality-trait looks like in leaders under pressure, anchored to the AI scale, would have been making cleaner claims. The article’s choice to invoke authentic-leadership-the-style instead means it inherits all the ALQ’s measurement problems without using the ALQ’s data.
I treated the build-versus-buy decision for instruments at length in my earlier post on custom versus off-the-shelf psychometric instruments. The decision rule there was that off-the-shelf is right when the constructs are well-served by validated instruments, and custom is right when the constructs are organization-specific. The authentic leadership case is a third category, where the off-the-shelf instrument exists but its validation status is contested, and the right move is often to look for an adjacent better-validated construct rather than to use the disputed one. Authenticity-the-trait is the adjacent construct here, and its scale is in better shape than the ALQ.
The pattern under all three constructs
The three articles share a structural feature that is easy to miss when you read them individually. Each one invokes a named construct, prescribes action, and gestures at validation by attaching the construct to a researcher or research tradition. None of them shows you the instrument or engages with the validation evidence. The construct is treated as if it has a clear meaning, the scale is treated as if it is uncontroversial, and the prescription is treated as if it follows.
For the empathy article, the issue is that the SJT exists but its methodological provenance is not engaged. For the psychological safety article, the issue is that the scale is excellent but is being extended to a context the validation does not yet cover. For the authentic leadership article, the issue is that the dominant scale’s validation status is genuinely contested and the article ignores the contest.
The pattern is the move that distinguishes leadership writing from assessment writing. Leadership writing names constructs as if they are facts in the world. Assessment writing tracks the construct back to the instrument that is doing the measurement, and treats the instrument as the part you have to actually evaluate. This is not academic finger-wagging. It is the difference between recommending a course of action that survives changes in the underlying evidence and recommending one that depends on a particular measurement choice that may not hold up.
I made the same form of argument in my critique of the Q12 engagement instrument, in my analysis of the experience-trait relationships found in two custom psychometric studies, in my walk-through of what NPS loses by collapsing the top of the rating scale, and in my treatment of leader-trait constructs like tolerance for ambiguity and locus of control. The pattern across those posts and this one is the same: name the construct, find the scale, look at the scale’s validation evidence, and ask whether the claims people want to make on top of it are claims the evidence supports.
What to ask the next time a leadership article names a construct
When you read a leadership article that invokes a named psychological construct, four questions are worth asking before you act on its prescription.
The first is what instrument the article’s claims rest on. If the article reports correlations or effect sizes, the data came from somewhere. Identify the scale.
The second is what the validation evidence for that scale looks like. For some scales, the answer is decades of work and broad professional consensus. For others, the answer is a contested literature with active methodological criticism. The two cases support different levels of confidence in claims downstream of the scale.
The third is whether the article is using the scale in the context the validation covers. Edmondson’s psychological safety scale was validated for human teams, and any application to AI-included teams is an extension that needs its own evidence. Many articles invoke a construct in a context different from the one its scale was built for, and the resulting claims inherit the gap.
The fourth is whether the prescription depends on the measurement claim or survives without it. A lot of practical leadership advice is robust to whatever resolution the underlying construct measurement reaches. Some of it is not. Knowing which is which is useful before you build a program around it.
These four questions are not a debunking exercise. They are a calibration exercise. The articles I walked through in this post are all worth reading. The frameworks they offer are practical. The thing reading them well requires is the discipline of treating the construct claims as separable from the prescription claims, and of giving the construct claims the scrutiny the instrument literature already gives them. That discipline is what makes a measurement professional useful, and it is the lens I bring to almost any leadership writing that names a psychological construct as if it were a fact rather than the output of a particular questionnaire administered to a particular population at a particular time.
Related reading
Discriminant Validity in Practice: How to Tell a New Construct From a Renamed One
Trust ambiguity, grit, and the test that separates a real construct from a relabel. Convergent and discriminant validity in practice, with a worked example.
Tolerance for Ambiguity, Locus of Control, and What These Leader Traits Actually Measure
Two HBR articles invoke leader traits as advice. The scales exist: IUS-12, tolerance for ambiguity, locus of control. What they actually predict for executives.
What Net Promoter Score Loses by Collapsing the Top of the Rating Scale
Marcus Buckingham called Net Promoter Score problematic in HBR. The reason is a rating scale measurement argument worth unpacking. What NPS loses and what to do.
Custom or Off-the-Shelf Psychometric Instrument?
When does a custom psychometric instrument earn its multi-week build cycle, and when is off-the-shelf personality assessment for hiring enough?